什么是知识图谱?
一种用图模型(probabilistic graphic models)来描述知识和建模世界万物之间的关联关系的技术方法。由节点和边组成
知识图谱的价值
- 辅助搜索
- 辅助问答
- 辅助大数据分析
- 辅助语言理解,人机之间的相互理解

这道看似简单的题,机器却毫无办法。“到底谁大谁小?”
5.辅助设备互联,机器与机器之间的相互理解书中一直强调的辅助作用,是不是意味着知识图谱更像一种锦上添花的工具?
一些知识图谱项目
freebase
wikidata(需要梯子)

如何构建一个规模化的知识图谱
值得注意的是阿里巴巴有自己的电商知识图谱,规模达到了百亿级别。
知识图谱的技术流程
- 知识图谱采用更加规范而标准的概念模型、本题术语和语法格式来建模和描述数据
- 通过语义链接来增强数据之间的关系
_就像是一张网。_知识图谱方法论涉及知识表示、知识获取、知识处理和知识利用多个方面。一般流程为:
- 首先确定知识表示模型,然后根据数据来源选择不同的知识获取手段导入知识
- 接着综合利用知识推理、知识融合、知识挖掘等技术对构建的知识图谱进行质量提升,
- 最后根据场景需求设计不同的知知识访问与呈现方法,如语义搜索、问答交互、图谱可视化分析等。
1.知识来源
有多种来源来获取知识,除了文本,我们还可以考虑结构化数据库、多媒体数据、传感器数据和人工众包。对于文本数据源,我们要用到自然语言处理技术。对于各种结构化数据库,需要将结构化数据定义到本体模型之间的语义映射,再通过编写语义翻译工具实现转化。
2.知识表示
即用计算机符号来表述人类的语言
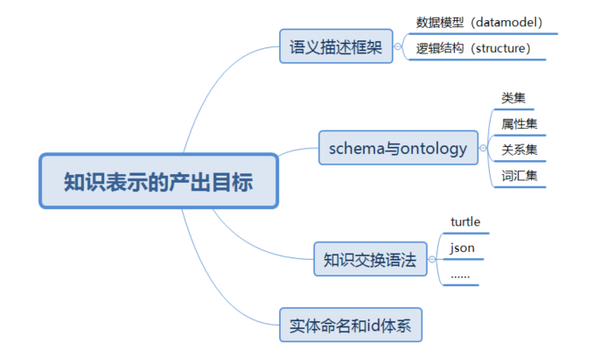
知识表示的产出目标
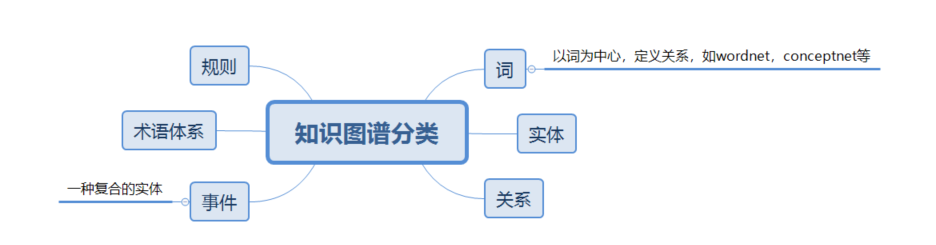
知识图谱分类
3.知识抽取
知识抽取按任务划分可以分为概念抽取、实体识别、关系抽取、事件抽取和规则抽取等
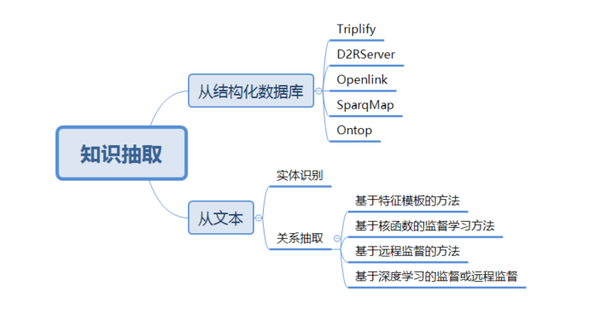
知识抽取的划分
书中解释了远程监督的思想远程监督的思想是,利用一个大型的语义数据库自动获取关系类型标签。这些标签可能是含有噪声的,但是大量的训练数据在一定程度上可以抵消这些噪声。另外,一些工作通过多任务学习等方法将实体和关系做联合抽取。最新的一些研究则利用强化学习减少人工标注并自动降低噪声。如何减少人工标注,是我现阶段工作的重点。
4.知识融合
外部数据库合并到本体知识库时,需要解决两个问题
- 通过模式层(?)的融合,将新的本体融入已有的本体库中,以及新旧本体的融合
- 数据层的融合,包括实体的指称、属性、关系和所属类别。
关键问题是如何避免实例以及关系的冲突问题,造成不必要的冗余
文中提到的本体概念,这边没有太理解,需要另找专门的文献再熟悉熟悉
5.知识图谱的补全和推理(重头戏)
6.知识检索和知识分析
包括语义检索和智能问答
知识图谱相关技术
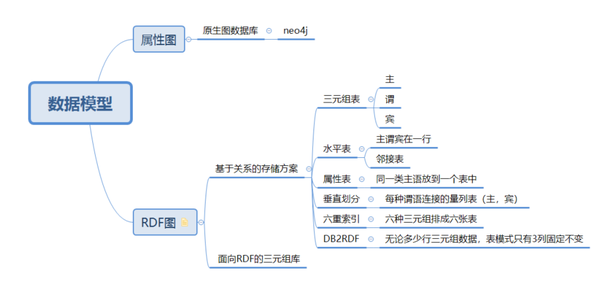
数据库与数据模型
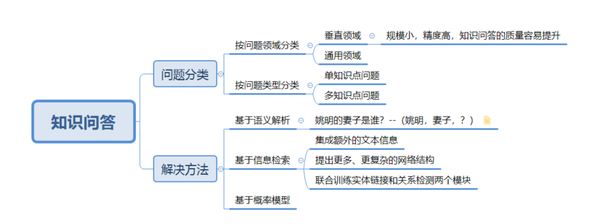
知识问答

知识推理
基于表示学习的知识图谱推理研究的主要研究趋势是,一方面提高表示学习结果对知识图谱中含有的语义信息的捕捉能力,目前的研究多集中在链接预测任务上,其他推理任务有待跟进研究;另一方面是利用分布式表示作为桥梁,将知识图谱与文本、图像等异质信息结合,实现信息互补以及更多样化的综合推理。如果说我们人的思维是一个已经存在的知识图谱,那么我们在学习知识的时候,基于知识表示的学习方法一定是更快的,相比于基于规则的推理而言,知识来源的渠道更广泛,更丰富,更能激发“兴趣”。后面还写到了推荐系统与去中心化,这里暂且不论。
第一章 完



