Project Debater的论述生成模块
首先我们来看一下论文使用了哪些语料来构建论述的
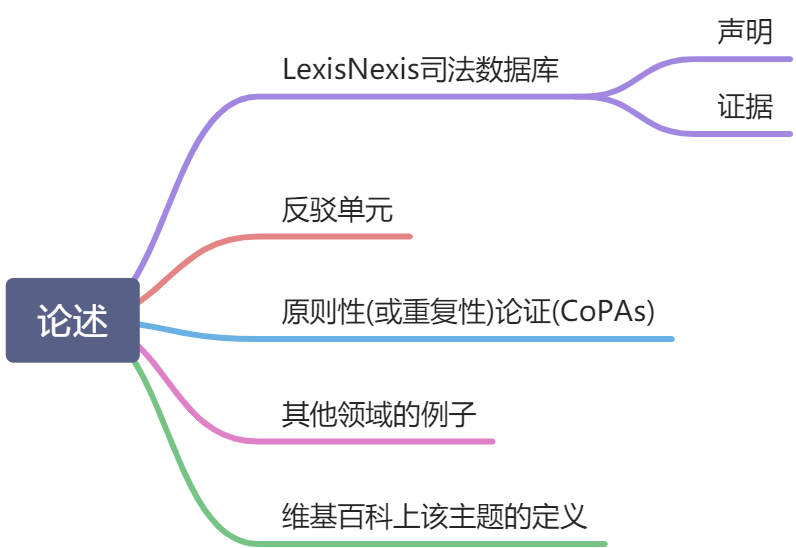
而论述的构建分为以下几个阶段
过滤元素
这里的元素指的是声明和证据
司法数据库中的声明和证据是由神经网络模型打分并且排序的,为了筛选出最符合的几项,一般的方法是设定一个通用的阈值。但这种做法存在两个问题
- 不同动议下这个阈值应当是不同的;
- 由于分数是神经网络给出的,无法通过概率去解释这个分数(Do not have a clear probabilistic interpretation)。
为了解决这个问题,文章提出了设置一系列的门槛,$threshold_k,k \in {60,70,80,90}$,在这个门槛之上的元素至少有$k%$的准确度,也就是说分数在$threshold_{80}$以上的文章有$80%$的准确度。为了实现这个分级,设计了两种算法:
针对声明,采用交叉验证(Cross Validation)的方法,具体如图
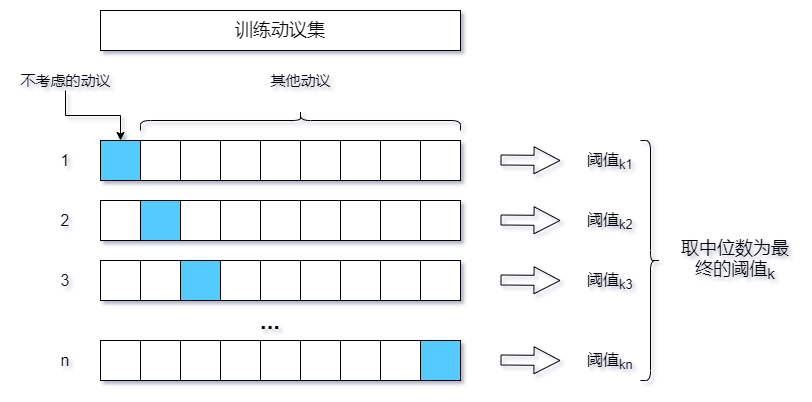
在每一轮中,除不考虑的动议之外,对其他动议中声明的分数以降序排列,找到能够满足准确度在$k%$以上的最小分数作为该轮的$threshold_k$,最后求取所有$threshold_k$的中位数,作为整体的$threshold_k$。
针对证据文本,使用线性回归模型拟合出每个动议的$threshold_k$。训练时以前30个候选元素的平均值作为特征,满足准确度在$k%$以上的最小分数作为标签。
在学习到需要的阈值之后,就可以将所有元素按照精确度进行划分,再进行人为选择。
最后再借助一个立场检测任务,过滤不合适的,太短的或太长的元素。
去重
来源于不同文章的元素可能表示了相同的观点,因此需要对其进行去重。文章提出了一种去重机制,这种机制将相似的论点聚集在一起且为下游任务保留了一个单独的代表。这个机制的运作方式如下:
- 每一个论点都由其Token的word2vec向量值进行表示,并且根据维基百科上的IDF值进行加权;
- 初始阶段,每个论点都被映射到单独的集群;
- 根据余弦相似度聚合两个相似的论点;
- 为每个聚类选取单独的代表,舍弃其他的论点。
聚类
有代表性的论点聚合成一个个的主题群,使得一个段落中能够呈现关于同一主题的论点。这里提到了三个现成的工具:
iClust算法 Slonim等人提出的一种以信息为基础的聚类算法
Slonim, N., Atwal, G. S., Tkaˇcik, G. & Bialek, W. Information-based clustering. Proceedings of the National Academy of Sciences 102, 18297–18302 (2005).
Wikifier 将论点转化为维基百科上的概念 Wikifier
WORT 衡量维基百科上概念相似度的工具
主题抽取
主题抽取模块的主要作用是识别每个聚类的主题,即维基百科上的标题,包括名词或者名词短语,如“Health、Economy”等,同时为主题找到可能存在的主题句(theme-claim)具体步骤可以分为:
使用Wikifier确定每一个论点包含的维基百科概念,这些概念又与某一主题相关;
使用超几何分布来评估每个主题在每个聚类中的富集程度,保留统计上富集程度高的标题;
什么是超几何分布?
作为离散概率分布的超几何分布尤其指在抽样试验时抽出的样品不再放回去的分布情況。在一个容器中一共有$N$个球,其中$M$个黑球,$N-M$个红球,通过下面的超几何分布公式可以计算出,从容器中抽出的n个球中(抽出的球不放回去)有k个黑球的概率是多少:
$$
f(k, n ; M ; N)=\frac{\left(\begin{array}{c}
M \
k
\end{array}\right)\left(\begin{array}{c}
N-M \
n-k
\end{array}\right)}{\left(\begin{array}{c}
N \
n
\end{array}\right)}
$$同时计算聚类中拥有相同标题或相似标题的论点数目。
通过以上手段来保证所选主题在聚类中是常见且相对唯一的。
重新措辞
这里是比较关键的部分,上文抽取到的所有论点,因为来自不同的文本,所以直接连接在一起也会显得非常不流畅。所以需要对文本进行重新措辞,包括:
- 对论点本身进行重新措辞,包括清除连接词、指代消解等;
- 对段落进行重新措辞,包括将一组短论点连接成一个单独的长论点,或者用指代第一个提及的代词替换在一组论点中重复出现的名词短语,即加上指代关系。
论点层面的重新措辞
文章提出了六十二种不一样的措辞器,他们都目标都是让论述尽可能的流畅。文中描述了两种:
第一个措辞器添加了对论点中出现的一些人物的描述,如
| Before | After |
|---|---|
| Bryan Caplan argues that higher education “is a big waste of time and money” and that “students spend thousands of hours studying subjects irrelevant to the modern labor market.” | Bryan Caplan, an economics professor at George Mason University argues that higher education “is a big waste of time and money” and that “students spend thousands of hours studying subjects irrelevant to the modern labor market.” |
这就使得论点的信息更加丰富,看起来更加可信
第二个措辞器用来将一些书面语口语化,如
| Before | After |
|---|---|
| “Scientists have abundant evidence that birth control has significant health benefits for women and their families, is documented to significantly reduce health costs, and is the most commonly taken drug in America by young and middle aged women,” U.S. Department of Health and Human Services Secretary Kathleen Sebelius said in a 2012 statement. | U.S. Department of Health and Human Services Secretary Kathleen Sebelius said in a 2012 statement that “Scientists have abundant evidence that birth control has significant health benefits for women and their families, is documented to significantly reduce health costs, and is the most commonly taken drug in America by young and middle-aged women”. |
论述生成
完整的论述主要由两部分组成,包括
- 段落:如问候、下定义、开场、结尾等;
- 规则:决定不同段落应该使用哪些语料,如何结合这些预料。
关于不同类别的段落,文章中举出了一个比较重要的例子:包含思想论点簇(clusters of minded arguments)的段落,具体到如何将这些段落转化成论述的流程,如图所示:
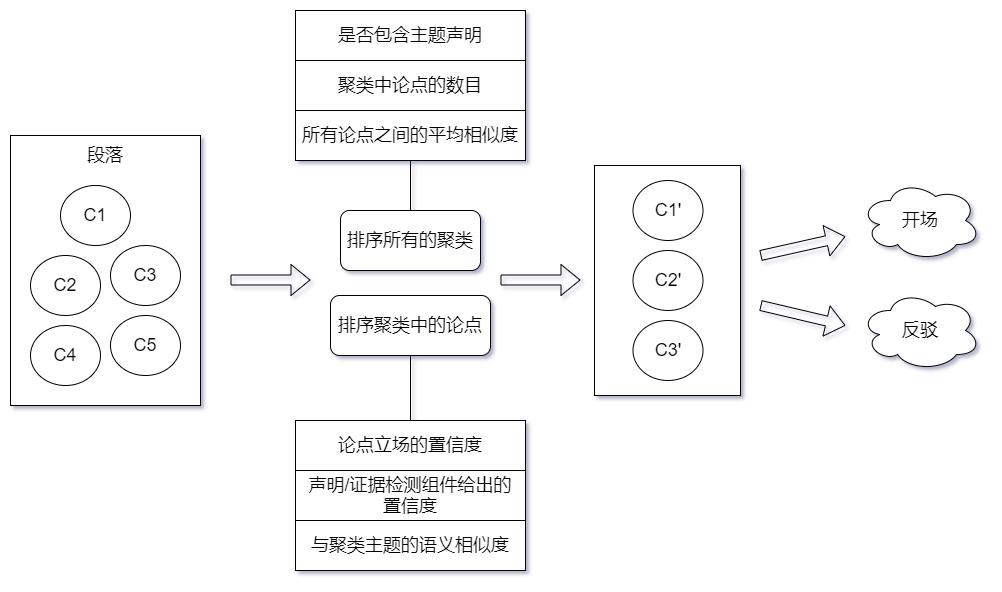
最后借助事先定义的模板来组织段落,生成完整论述。包括开场、反驳、总结都有其特有的模板,决定了这三者有特有的发言结构。文章中也给出了这些模板的形式,我这就不写了!
总结
这并不是一个通用的语言生成系统,作者对许多地方都定义了各种规则。但是还有比较多的处理方式可以供我们学习,简单罗列一下:
- 交叉验证(Cross Validation)方法确定阈值;
- 线性回归模型拟合阈值;
- IClust、Wikifier、WORT ;
- 使用超几何分布来判断聚类中某种元素的富集程度。



