标题:Universal Representation Learning of Knowledge Bases by Jointly Embedding Instances and Ontological Concepts
来源:KDD ‘19: Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining
地址:https://dl.acm.org/doi/10.1145/3292500.3330838
代码地址:https://github.com/JunhengH/joie-kdd19
许多大型的知识库都同时表示知识图谱的两个视图,包括用来表示摘要或者常识的本体视图,和用来表示从本体中提取出来的特殊实体的实例视图。但是没有将两个视图单独表示出来的知识嵌入模型。该研究提出了two-view KG嵌入模型JOIE,目的是为了实现更好的知识嵌入以及支持依赖于多视图知识的新应用程序。
背景
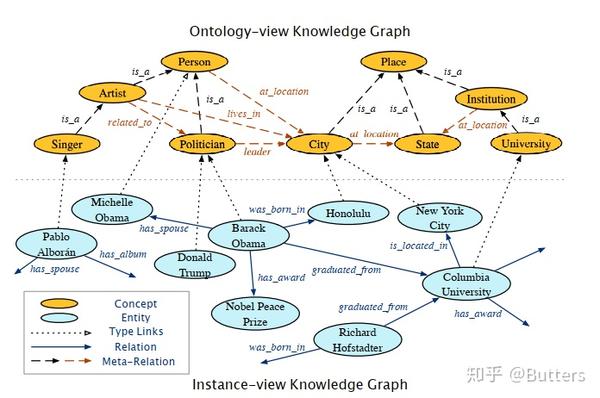
图1 双视角知识库示例。本体视图中橙色虚线表示层次元关系,黑色为规则元关系。
现存的知识图谱都可以分成如图1所示的两个视图
- 实例视图的知识图谱,例如(“Barack Obama”,“isPoliticianOf ”, “United States”)
- 本体视图的知识图谱,例如(“polication”, “is leader of ”, “city”)
同时,实例与本体视图之间由**视图间(cross-view)**关系来连接。
近年来对知识图谱的嵌入模型也有很多研究,但现有的模型都只针对其中一种视图进行设计。如果将双视图引入到知识表示模型中,可以有如下两点优势:
- 实例嵌入为其相应的本体上的概念提供了详细而丰富的信息。例如,通过观察多个音乐家个体(instance)的嵌入,很大程度上可以确定其对应的概念(concept)“音乐家”的嵌入。
- 概念嵌入对其实例进行了高层次的总结,当一个实例很少被观察到时,这将会变得非常有帮助的,例如对于某个在实例视图中几乎没有关系的音乐家,我们仍然可以知道他/她在实例嵌入空间中的粗略位置,因为他/她不会离其他音乐家太远。
模型
Challenge:
- 实例与概念、关系与元关系之间虽然不相交,但是存在语义上的联系,且两者做映射非常复杂。
- 现有的视图间关系往往不足以覆盖大量的实体,导致没有足够的信息区对齐两个视图,同时也限制了视图间发现新关系的能力
- 两种视图的规模和拓扑结构也有很大不同,其中本体视图通常是稀疏的,提供较少类型的关系,并形成分层的子结构,而实例视图则更大并且具有更多的关系类型。
Solution:
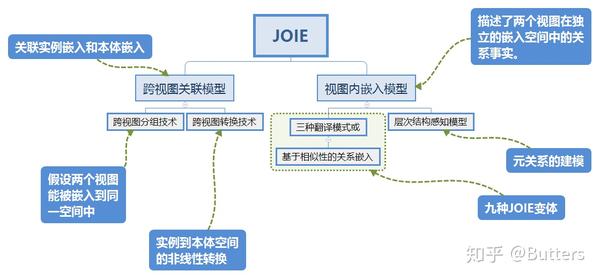
图2 JOIE模型结构
建模
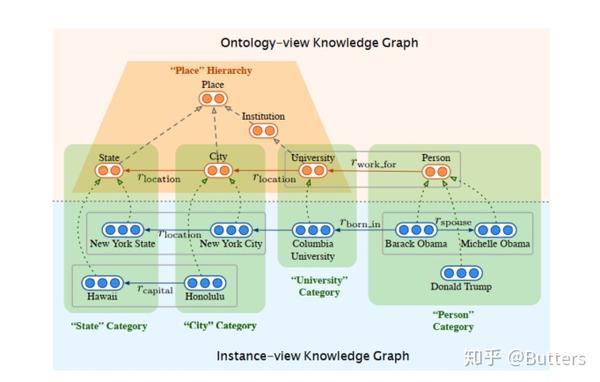
图3 跨视图关联模型从跨视图链接(绿色“类别”框中的虚线箭头)学习嵌入。默认的视图内模型从每个视图中的三元组(灰色框)中学习嵌入。层次结构感知的视图内模型对在本体(或“层次结构”梯形)中形成层次结构的元关系事实进行建模
跨视图关联模型
- Cross-view Grouping (CG)——跨视图分组技术
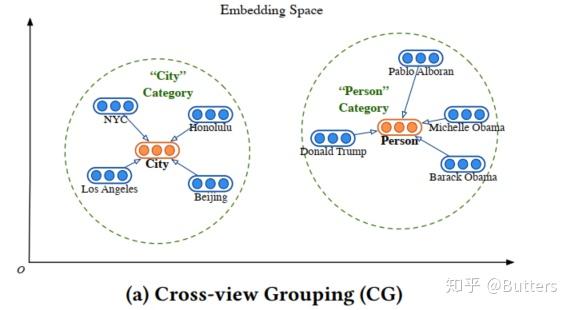
图4 跨视图分组技术
如图4所示,跨视图分组技术会假设本体视图的知识图谱和实例视图的知识图谱能够嵌入到同一空间中,并且“迫使”属于概念c的实例e在表示空间上靠近概念c。以此定义学习的loss为:
(1)
式中S表示具有is_A关系的实例与概念关系对; 表示训练的超参数,也是图4中圆的半径;
。式(1)表示如果e出离了c圆之外,就会产生惩罚。
- Cross-view Transformation (CT)——跨视图转换技术
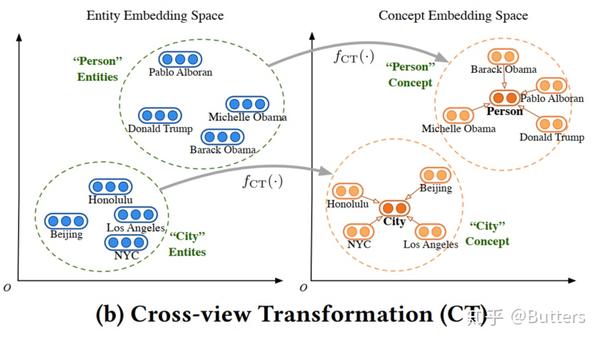
图5 跨视图转换技术
和CG不同的是,CT允许两个视图彼此完全不相同,通过转换之后将两个视图对齐在一起。也就是说,转换之后,一个实例的嵌入将会被放置在本体视图中,且靠近该实例所属的概念嵌入。即
(2)
这里的 是一个非线性的仿射变换[1],由此定义loss
(3)
视图内嵌入模型
视图内模型的目的是在两个嵌入空间中分别保留KB的每个视图中的原始结构信息。由于实例视图中的关系和本体视图中的元关系的语义含义不同,因此有助于为每个视图提供单独的处理方式,而不是将它们组合为单个表示模式,从而提高了性能。文中提供了两种嵌入模型。
- Default Intra-view Model——默认内部视图模型
即通过现有的知识图谱表示模型来进行学习,包括TransE,DistMult,HolE,其得分函数如(4)
(4)
优化目标即最小化所有三元组(包括实例间三元组和概念间三元组)的loss:
(5)
其中 表示表示头尾被替换,不存在于图谱中的三元组。这个损失天然就适用于两个不同的视图,我们用两个视图的损失函数构建一个联合损失函数:
(6)
式中的α1用来调节权重
- Hierarchy-Aware Intra-view Model for the Ontology. ——本体的层次感知视图内模型
默认内部视图模型并不能对本体视图的概念间上下位关系进行很好的建模。作者提出了层次感知视图内模型,这一模型进一步区分了形成本体层级结构的元关系(如”subclass_of”和”is_a”)和视图内模型中常规的语义关系(如”related_to”)。
这里设计方法类似CT,即给定一个具备subclass_of关系的概念对 ,认为存在非线形变换可以将粗粒度的概念(上位概念)映射为细粒度的概念(下位概念),其公式可以表示:
(7)
式中的都是训练的参数。由此定义的loss为
(8)
再列出联合loss
(9)
式中 表示使用默认内部视图模型再常规语义关系三元组上训练所得到的损失。
表示在具有本体关系层次结构的元关系的三元组上进行了明确的训练之后得到的损失,这与等式6有很大不同。
联合训练
(10)
式中ω是一个大于零的正参数,用来平衡两个J。
文中还讲到了他们的训练手法
Instead of directly updating J, our implementation optimizes JIntra GI , JIntra GO and JCross alternately. In detail, we optimize θnew ← θold - η∇JIntra and θnew ← θold - (ωη)∇JCross in successive steps within one epoch.η is the learning rate, and ω differentiates between the learning rates for intra-view and cross-view losses.
实验
- 数据集
数据集方面,由于现有方法大多只关注对一个视图的知识建模,缺少融合两个视图特点的公开评测数据。所以作者从YAGO和DBpedia构建了两个更符合真实知识图谱结构的数据集YAGO26K-906和DB111K-174。数据集的相关信息统计如下[2]:

表1 数据集概览
主要完成了知识图谱补全和实体分类的两个任务,都显示了该模型有不错的性能。这里篇幅有限,就不给人家打广告了。



