0 背景介绍
论文作者:姜天文
论文标题:条件性知识图谱构建及其应用研究[博士学位论文]
作者单位:哈尔滨工业大学
发表时间:2021
论文DOI:10.27061/d.cnki.ghgdu.2021.000447.
相关期刊论文:Jiang T , Zhao T , Qin B , et al. The Role of “Condition”: A Novel Scientific Knowledge Graph Representation and Construction Model[C]// the 25th ACM SIGKDD International Conference. ACM, 2019.
在知识图谱发展的早期阶段,知识体系和任务场景都是相对明确的,实例类型和关系类型都由预先定义得到。这类构建在封闭域中的知识图谱。伴随着信息量的爆炸式增长,人们往往无法预知知识图谱的关系体系以及其中的实体类型,依托于信息抽取技术的开放式知识图谱应运而生。开放式的知识图谱具有以下特点:
- 实体定义的边界条件更加宽松;
- 使用文本中的关系指示词来表达实体之间的隐式关系;
- 对文本中的知识表征更加完整;
无论是封闭域还是开放式知识图谱,都着重专注于事实三元组的抽取和表示,然而这种表示方式是不全面的。文章中举了两个非常形象的例子,如下图所示:

根据该论文的介绍,条件性知识图谱的意义至少包含了以下三点:
- 提出了一种语义更完整的知识图谱形式;
- 更充分地利用文本知识;
- 在事实推理的场景下,推理结果的可解释性和可验证性有望得到保障;
该论文的框架和创新点如下图所示:
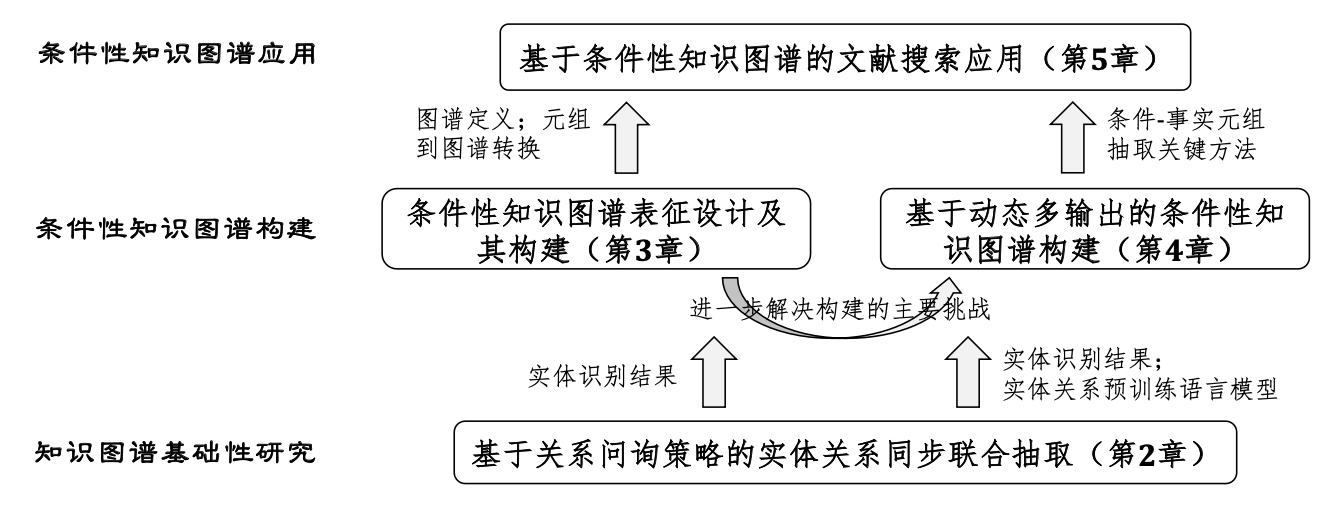
1 条件性知识图谱结构
上图是该论文所提出的条件性知识图谱的层次化网状结构,它看起来还是比较复杂的,难以直观理解。所以我们先从条件性知识图谱的定义入手了解其含义,再来理解这个“层次化”结构。文中所给出的定义如下:
条件元组和事实元组的定义
$$ t=\left(\left\{e_{1}: a_{1}\right\}, r,\left\{e_{3}: a_{3}\right\}\right) $$式中$e_{1}, e_{3} \in{n u l l}+\mathcal{E}, r \in \mathcal{R}$以及$a_{1}, a_{3} \in{n u l l}+\mathcal{A}$。其中$\mathcal{E}、\mathcal{R}、\mathcal{A}$分别是实体、谓词和属性的集合。$null$则表示实体和属性为空。
实体属性为空的情况很好理解,比如关于事实的描述”碱性pH增加TRPV5/V6通道的活性“,可以结构化为**$e_1=\text{碱性}pH、a_1=null、r=增加,e_3=TRPV5/V6通道、a_3=活性$**。
但为什么会存在实体为空但属性不为空的情况呢?论文结合了一个条件文本的实例进行了解释:对于条件的描述”在T淋巴细胞活化以及细胞因子产生的过程中,……“,其中包含了两部分的条件元组:
条件 1:$(null$, 过程中, $\{$T淋巴细胞:活化$\})$
条件 2:$(null$, 过程中, $\{$细胞因子:产生$\})$
可见在用三元组对条件进行表示时,的确会存在主语(三元组的头部实体)缺失的情况。
文本的条件-事实的结构化定义
对于给定的句子,可以将其结构化为条件和事实三元组的列表,同一个句子中的条件和事实之间存在着依赖关系,该关系可以表示为:
$$
s=\left[t_{1}^{(f)}, \ldots, t_{n}^{(f)} ; t_{1}^{(c)}, \ldots, t_{m}^{(c)}\right]
$$
式中$s$表示特定的语句,$t_{i}^{(f)}(i \in{1, \ldots, n})$代表第$i$个事实元组,$t_{j}^{(c)}(j \in{1, \ldots, n})$代表第$j$个条件元组。具体结合上文的例子。给定描述语句“如果患者的感冒是由于风寒引起,这种情况下可以喝姜糖水,因为生姜具有发散风寒的作用,对于感冒症状具有很好的缓解作用“,该句子可以结构化表示为
$$
s=[t_{1}^{(f)}=(姜糖水,缓解,感冒症状);t_{1}^{(c)}=(风寒,引起,感冒)]
$$
条件性知识图谱的定义
论文将条件性知识图谱的结构分为三个层次,包括实体层、关系元组层和句子层,每一层具体含义如下:
- 实体层:$L_{\mathcal{E}}=\left(\mathcal{E} \cup \mathcal{A}, E_{\mathcal{E}, \mathcal{A}}\right)$,实体层的节点可以分为属性节点和实体节点,即如果a是e的属性,则两者之间存在关系$E(e, a) \in E_{\mathcal{E A}}$,在图中的标注为$attr.$;
- 关系元组层:$L_{\mathcal{R}}=\mathcal{R}$,$\mathcal{R}$为关系节点的集合,依据三元组的集合与实体层进行链接。链接的方式可以简单的概括为,制定关系节点的主语和宾语,两种链接关系在图中标识为$subj.$和$obj.$;
- 句子层:$L_{\mathcal{S}}=\mathcal{S}$,$\mathcal{S}$表示公式(2)中结构化语句$s$的集合,句子层和关系元组层之间使用”条件“和”事实“两类关系连接;
2 条件性知识图谱构建
上一节介绍了该论文是如何定义条件性知识图谱结构的,这一节主要介绍论文是如何从文本中实现对上文所提到的元组进行抽取的。首先,论文认为对文本中元组抽取问题可以转换为序列标注(标签预测)问题。该问题主要的三个挑战包括:
同时存在于事实元组合条件元组中的词例存在着冲突标签;
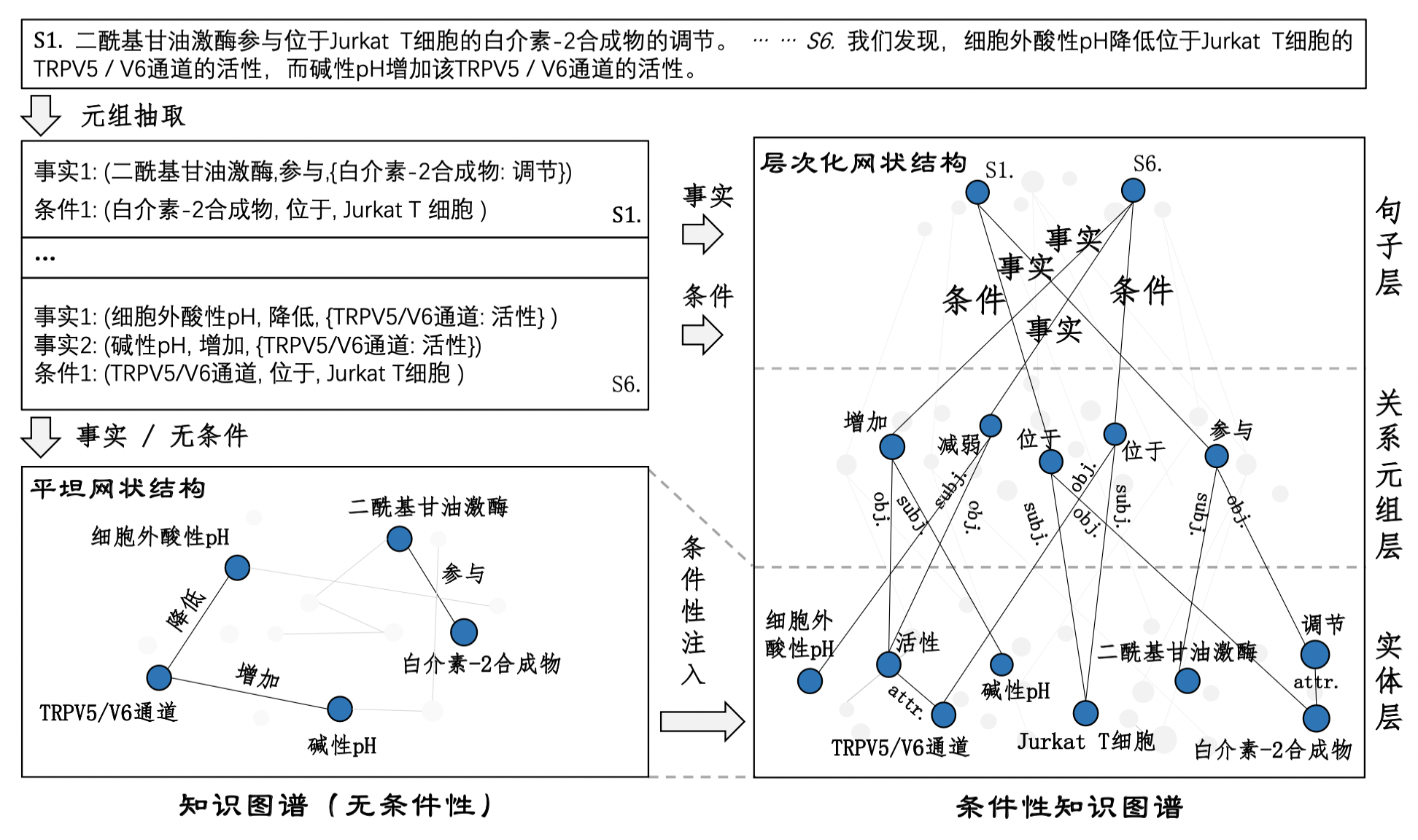
对于描述语句“我们发现,碱性pH 会增加位于 JurkatT 细胞的TRPVS/6通道的活性”,其包含的事实和条件分别为:
事实: (碱性pH, 增加, {TRPV5/V6通道:活性 });条件: (TRPV5/V6通道, 位于, JurkatT细胞)
“TRPV5/V6通道”在事实元组中是宾语,而在条件元组则作为主语存在,这意味着图谱构建模型的输出至少应当是基于双输出序列的标注,即区分事实和条件序列。
人工标注的代价较大;
主要原因是现有的知识库并没有相关的条件信息,同时这也意味着人工标注的数据量有限。
序列标注的噪声导致其转换为元组时结果存在二次损失;
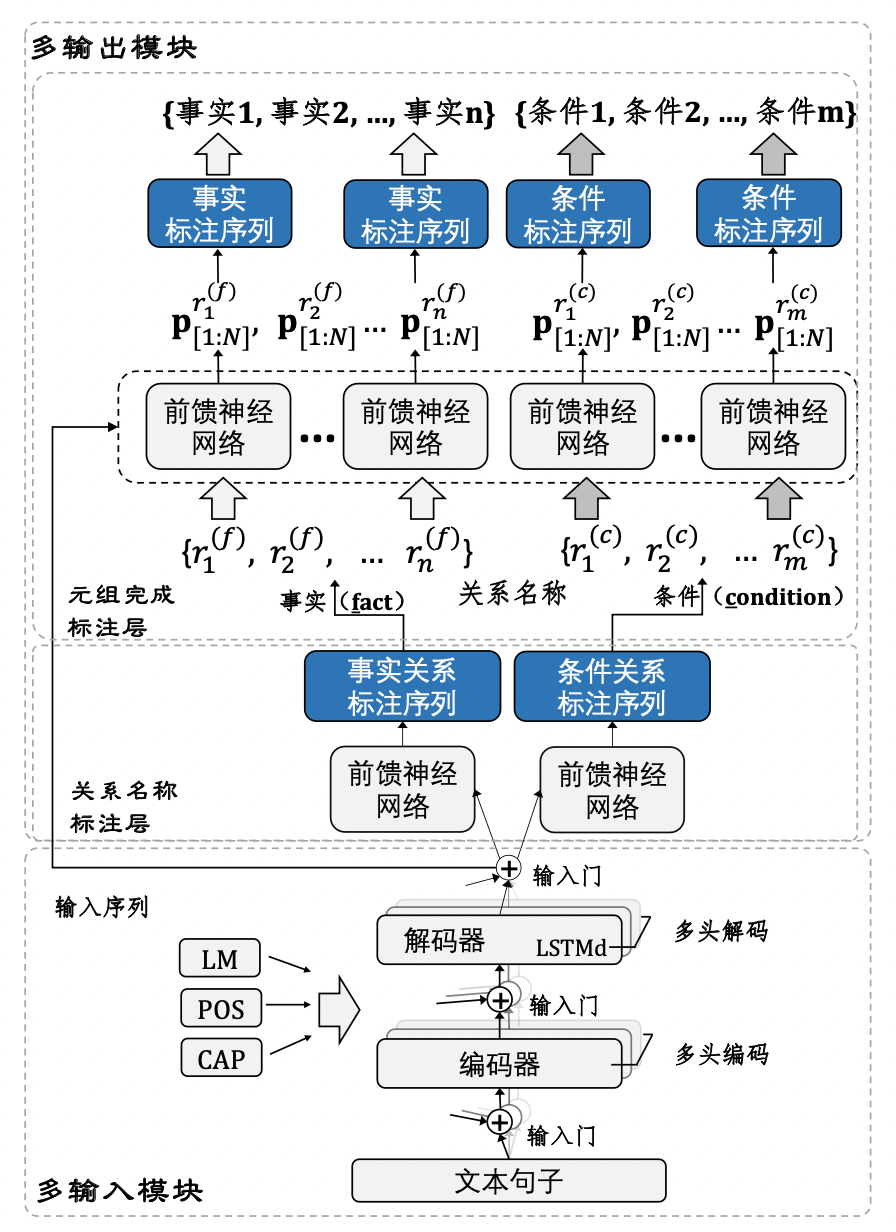
基于半监督多输入条件-事实双输出序列标注模型
对于上述挑战,文章提出了下图所示的基于半监督多输入条件-事实双输出序列标注模型:
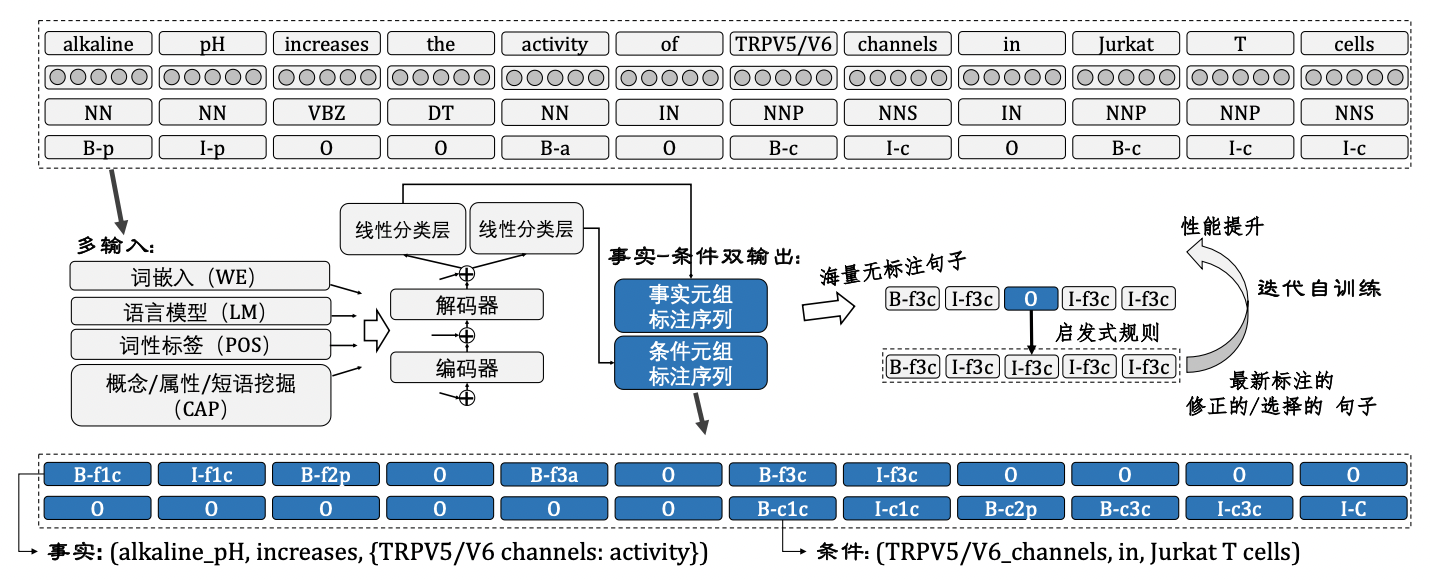
根据论文的内容总结该模型的特点:
标签的定义如下图所示:

事实/条件双输出,两者使用相同的序列编码器和解码器(网络结构为BiLSTM),但使用不同的线性分类层预测具体的标签(预测概率分布)。
多输入模块,如上图所示,该模型的输入分为四个部分。论文提出采用多输入主要是为了解决监督数据稀缺的问题,不同模块的作用也不同。
- 词嵌入(WE):通过上下文信息获取词例与前序词之间的依赖关系,如判断“alkaline”和“pH”是否属于同一个实体。论文所采用的词嵌入方法为GloVe;
- 语言模型(LM):主要作用是保证长序列中词例与前序词之间的依赖关系,有助于主谓宾关系的建模。论文在实验部分采用了BER作为预训练的语言模型;
- 词性标签(POS):为句子中的每一个词例分配其在文本中的词性(如形容词、名词和动词),隐式地反映了词语之间的依存关系;
- 实体/属性/短语挖掘(CAP):判断词例的语义角色,如判断哪些实体为”概念“,哪些实体为”属性“;
迭代自训练,包括基于关联规则的更正、基于标签一致性的校正、仅短句和删除不完整序列四个部分。前两者的校正策略实例如下图所示:
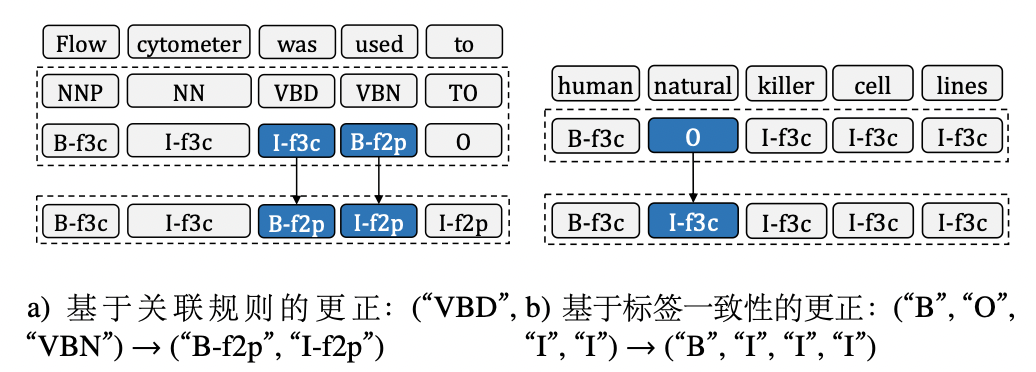
图中所展示的修正规则可以表示为:a. 一些词性标签的形式和输出标签有很强的顺序关系,如[NNP,NN,VBD, VBN]→[B-f1c,I-f1c,B-f2p,I-f2p],根据这类规则对预测标签进行修改;b. BOII这种模式是错误的,需要对其进行修改;
而所谓仅短句则是通过较短的局子来让模型的训练更加可靠。
上述内容来源于该博士论文的第三章,也是论文《The Role of “Condition”: A Novel Scientific Knowledge Graph Representation and Construction Model》的主要内容。在第四章中,论文进一步针对条件性知识图谱的构建模型进行了创新。
基于多输入动态多输出的序列标注模型
论文首先提出了上一节所述模型存在的不足,包括:
- 上述模型只能解决条件元组和事实元组的重叠问题,并不能根治同类元组的重叠问题;举例说明,描述语句“库克是科技公司Apple的CEO”,包含了两个事实元组“(库克,CEO,Apple)”,“(Apple,是,科技公司)”,Apple在两个元组中有不同的角色,导致对其进行标签预测时可能会发生错误;
- 半监督模型仍旧无法摆脱对人工策略的依赖;
对此,论文提出了如下图所示的基于动态多输出的序列标注框架:
3 条件性知识图谱的应用
论文将其提出的条件性知识图谱应用在了文献搜索任务上,选择生物医药作为目标领域。论文使用了下图描述文献搜索要实现的任务目标,并称之为CTGA系统,同时也给出了该系统的工作流程:
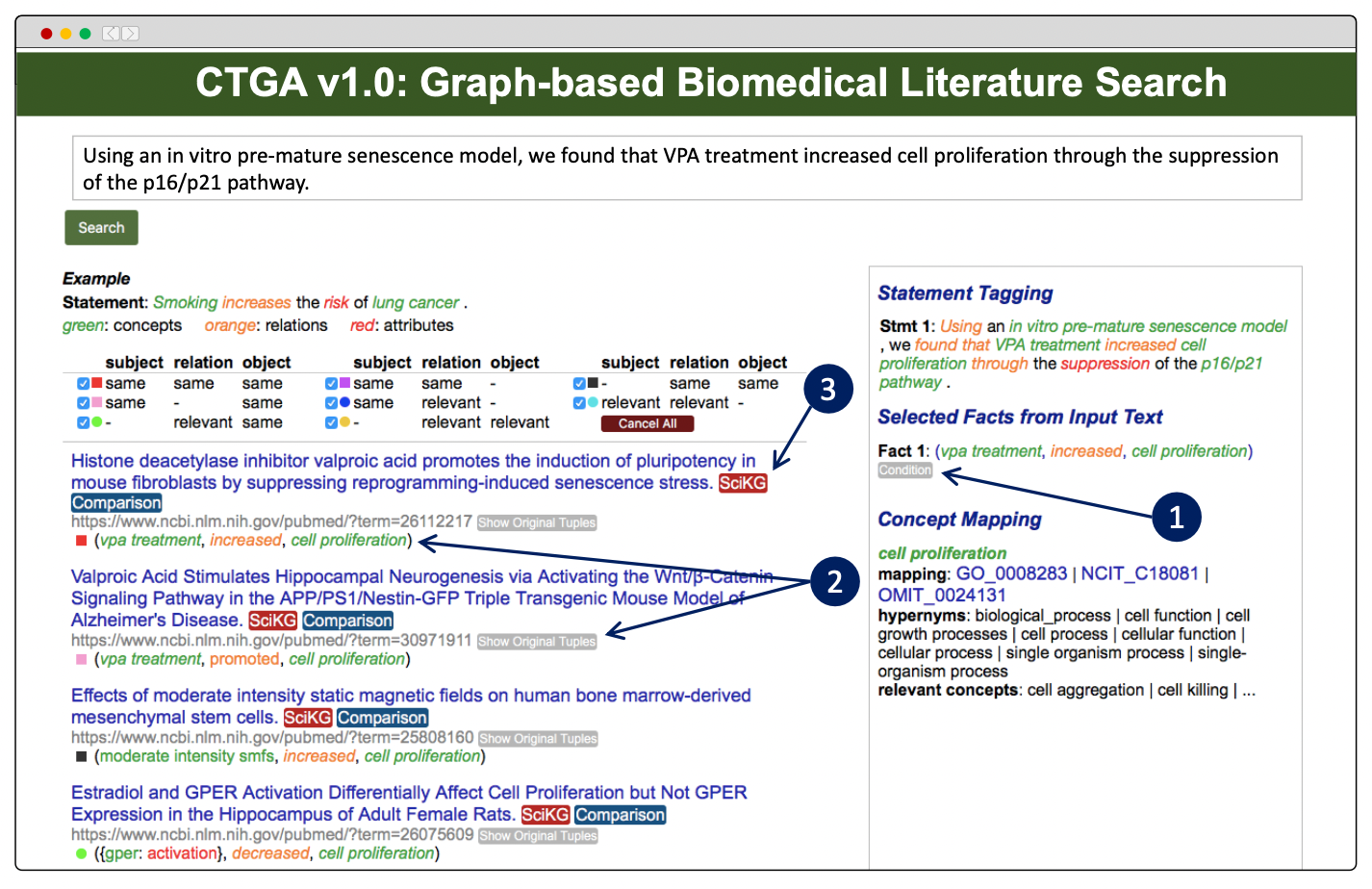
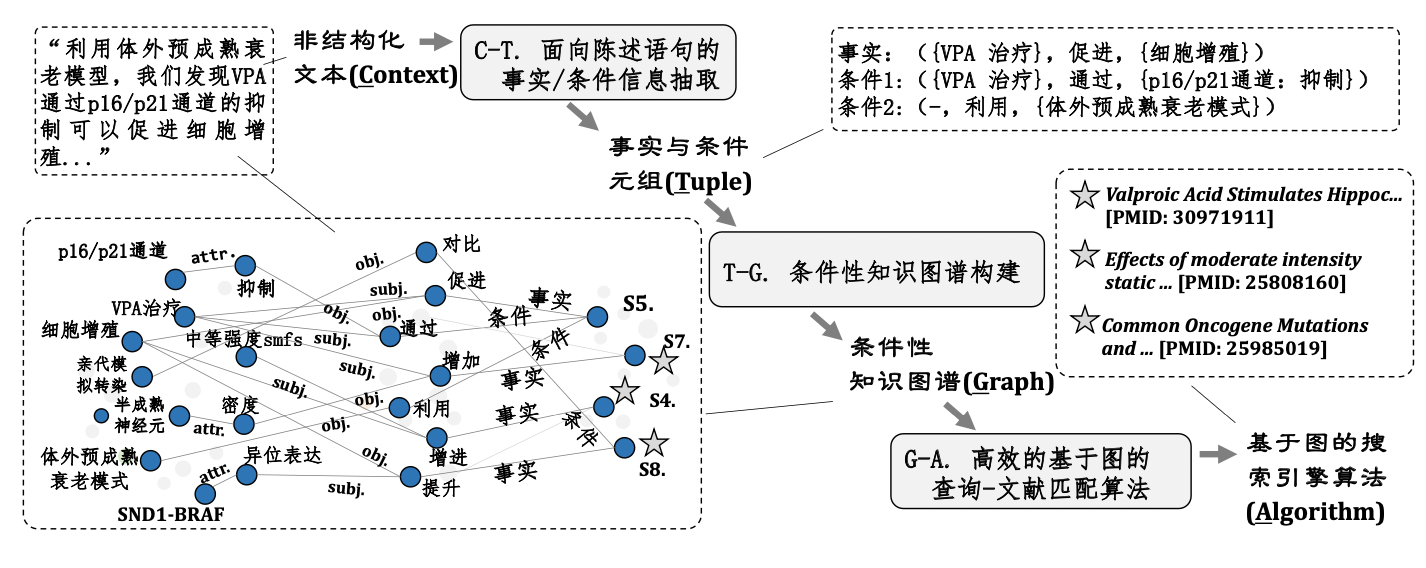
在方法层面,论文提出了两个不同检索模型。
基于条件性知识图谱路径匹配的文献搜索
基于路径匹配的搜索,其核心是对图谱中最常见的路径主语,宾语,谓语进行相似度匹配,结合以下公式对该搜索方法进行解释:
$$
\mathcal{P}^{(f)}=\left(a_{1}, E^{\mathrm{attr}}\left(e_{1}, a_{1}\right), e_{1}, E^{\mathrm{subj}}\left(r^{(f)}, e_{1}\right), r^{(f)}, E^{\mathrm{obj}}\left(r^{(f)}, e_{3}\right), e_{3}, E^{\mathrm{attr}}\left(e_{3}, a_{3}\right), a_{3}\right)
$$
$$
\mathcal{P}^{(c)}=\left(a_{1}, E^{\mathrm{attr}}\left(e_{1}, a_{1}\right), e_{1}, E^{\mathrm{subj}}\left(r^{(c)}, e_{1}\right), r^{(c)}, E^{\mathrm{obj}}\left(r^{(c)}, e_{3}\right), e_{3}, E^{\mathrm{attr}}\left(e_{3}, a_{3}\right), a_{3}\right)
$$
论文把这样的$\mathcal{P}$称为知识携带路径,$\mathcal{P}^{(f)}$和$\mathcal{P}^{(c)}$分别为事实和条件的知识携带路径。论文将查询图与文献图之间的事实相关性定义为事实知识携带路径准确率和召回率的调和平均值:
$$ \operatorname{Precision}_{\mathcal{K}^{\mathrm{q}}, \mathcal{K}^{\mathrm{d}}}^{(f)}=\frac{\sum_{i=1}^{N} \max _{j=1,2, \ldots, M} \phi\left(\mathcal{P}_{i}^{(f)}, \mathcal{P}_{j}^{(f)}\right)}{N} $$ $$ \operatorname{Recall}_{\mathcal{K}^{q}, \mathcal{K}^{\mathrm{d}}}^{(f)}=\frac{\sum_{j=1}^{M} \max _{i=1,2, \ldots, N} \phi\left(\mathcal{P}_{i}^{(f)}, \mathcal{P}_{j}^{(f)}\right)}{M} $$$$
\text { Relevance }_{\mathcal{K}^{\mathrm{q}}, \mathcal{K}^{\mathrm{d}}}^{(f)}=\left(1+\beta^{2}\right) \frac{\text { Precision.Recall }}{\beta^{2} \cdot \text { Precision+Recall }}
$$
其中N和M分别为查询和文献中所监测到的事实知识携带路径数, $\phi\left(\mathcal{P}_{i}^{(f)}, \mathcal{P}_{j}^{(f)}\right)$ 表示计算一对路径相似度的函数。准确率可以理解为有多少路径被检索到,召回率则体现了有多少路径的信息在文献中没有体现。对条件知识携带路径进行相同的操作,得到 $\text { Relevance }_{\mathcal{K}^{\mathrm{q}}, \mathcal{K}^{\mathrm{d}}}^{(c)} $ ,及查询图和文献之间的条件相关性。最终的查询和文献图之间的相似性可以定义为:
$$ \text { Relevance }_{\mathcal{K}^{\mathrm{q}}, \mathcal{K}^{\mathrm{d}}}=\lambda \cdot \text { Relevance }_{\mathcal{K}^{\mathrm{q}}, \mathcal{K}^{\mathrm{d}}}^{(f)}+(1-\lambda) \cdot \text { Relevance }_{\mathcal{K}^{\mathrm{q}}, \mathcal{K}^{\mathrm{d}}}^{(c)} $$至于如何判断路径的相似程度,文章定义了如公式(10)所示的函数:
$$ \begin{aligned} \phi\left(\mathcal{P}_{i}, \mathcal{P}_{j}\right) &=\operatorname{sim}^{c}\left(e_{i, 1}, e_{j, 1}\right)+\operatorname{sim}^{w}\left(a_{i, 1}, a_{i, 1}\right) \\ &+\operatorname{sim}^{c}\left(e_{i, 3}, e_{j, 3}\right)+\operatorname{sim}^{w}\left(a_{i, 3}, a_{i, 3}\right) \\ &+\operatorname{sim}^{w}\left(r_{i}, r_{j}\right) \end{aligned} $$其中,$sim^c$用来计算概念之间的相似程度,可以表示为:
$$ \operatorname{sim}^{c}\left(u_{i}, u_{j}\right)=\left\{\begin{array}{lr} 1, & \text { if } \operatorname{Synonym}\left(u_{i}, u_{j}\right) \\ \mathbf{u}_{i} \cdot \mathbf{u}_{j}, & \text { if } \operatorname{ShareHypernym}\left(u_{i}, u_{j}\right) \\ 0, & \text { otherwise } \end{array}\right. $$其中$\mathbf{u}_{i} \cdot \mathbf{u}_{j}$表示计算相应文本之间向量表示的点乘(衡量向量相似度),“Synonym”或“ShareHypernym”表示 $u_i$ 和 $u_j$ 是同义词还是彼此共享同一上位词。如何确定两次之间的关系,论文借助了外部的数据库。
同义词相对好理解,如”桂圆“和”龙眼“是同义词;而共享上位词一般的情况为同属于一类,如”荔枝“和”桂圆“有共同的上位词”水果“
而对于属性节点的相似度,论文采用下式进行计算:
$$ \operatorname{sim}^{w}\left(u_{i}, u_{j}\right)=\mathbf{u}_{i} \cdot \mathbf{u}_{j} $$基于条件性知识图谱表征学习的文献搜索
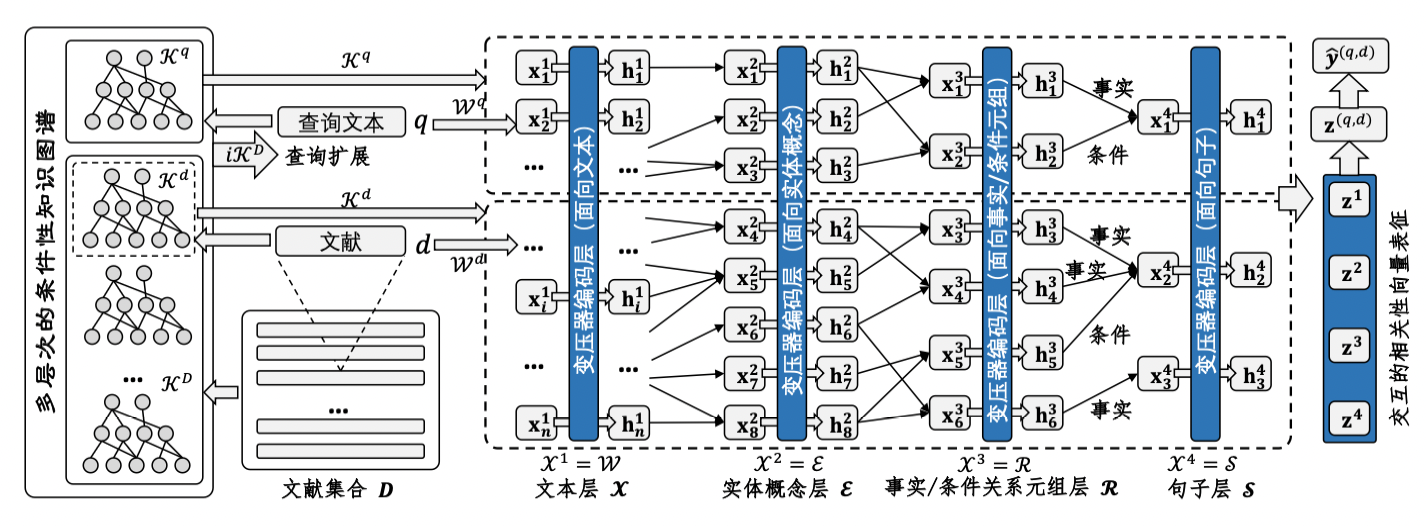
在该阶段,文章使用了上述模型以知识表征的方式搜索相似文献,但这一段专业性较强,这一段的专业性较强,我并没有太理解。



